


Grok4的代码水平不是第一梯队 实际演示现低级错误
Grok4的代码水平并非顶尖,实际演示中出现了低级错误,尽管可能存在一些误解或期望过高的情况,但从技术角度来看,Grok4的代码表现并不属于第一梯队,在实际操作或演示中,出现了不应该出现的低级错误,这也提醒我们在评估技术实力时需全面考虑其实际表现。
Grok4的代码水平不是第一梯队 实际演示现低级错误!尽管发布会推迟了近一个小时,xAI创始人马斯克在北京时间9月10日中午发布了新一代大模型Grok 4。这款新模型在传统基准测试、SAT考试及各学科的GRE水平测试中全面超越了竞争对手,包括OpenAI o3、Gemini 2.5 Pro和Claude 4等顶级大模型。此外,Grok 4还在被称为“人类最后一场闭卷考试”的HLE测试中取得了最高44.4%的准确率。

马斯克在直播中表示,Grok 4比几乎所有学科的研究生都更聪明,在学术问题上也优于所有学科的博士水平。他还提到,Grok 4基础模型的第七版将在本月完成,并将进行后训练强化学习,最终具备出色的视频理解和工具调用能力。未来几个月,xAI还将推出代码模型、多模型智能体以及视频生成模型。此外,xAI还推出了更高等级的订阅服务SuperGrok Heavy,用户可以使用最强模型Grok 4 Heavy。

然而,在实际演示过程中,Grok 4仍会出现一些低级错误。更引人关注的是,就在Grok 4发布前几个小时,xAI首席科学家Igor Babuschkin突然宣布辞职。
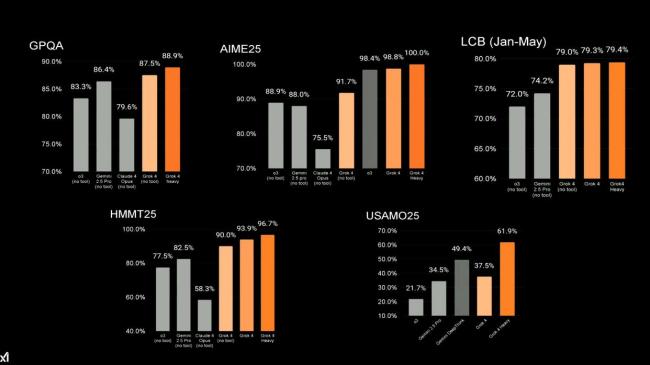
从技术角度来看,Grok 4不仅是一次常规迭代,而是一个挑战人类智能的新模型。它在AIME25、HMMT25、GPQA等主流基准测试中表现优异,Grok 4 Heavy甚至在AIME25上拿下了满分。在ARC-AGI和HLE测试中,Grok 4也展示了强大的学习能力和专业水平。例如,在HLE测试中,Grok 4的准确率达到25.4%,在借助工具的情况下进一步提高到44.4%。
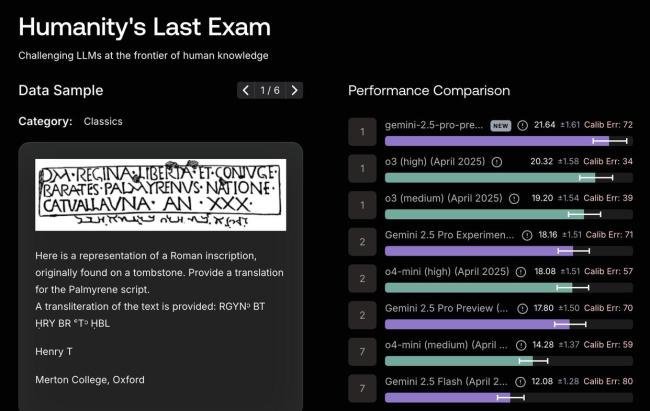
现场演示中,Grok 4展示了对HLE测试中专家级题目的准确性,马斯克认为只有极少数人能答对这些问题。此外,Grok 4在商业场景模拟测试Vending-Bench中也表现出色,其运营效率高于真人,创造的净值是真人的五倍以上。

直播中,Grok 4还进行了多项演示,包括实时抓取X平台上的帖子并整理出参与HLE测试的时间线,或找出xAI团队中头像最古怪的成员。这些演示展示了Grok 4的能力及其与X平台深度整合的优势。

另一个亮点是Grok 4对2025年MLB世界大赛冠军的分析预测,耗时近4分半。Grok 4还能遍览关键论文和资料来开发网页,模拟两个黑洞接触的变化。马斯克表示,未来他们将为Grok 4提供专业的物理拟真软件,预测其明年可能发现新的物理定律。
Grok 4还展示了对多模态输入的部分能力,尽管图像理解和生成能力尚未正式演示,但马斯克强调正在训练。这意味着Grok 4的完整形态将是多模态大模型,适用于更多现实场景,如人形机器人、自动驾驶和科研建模等。

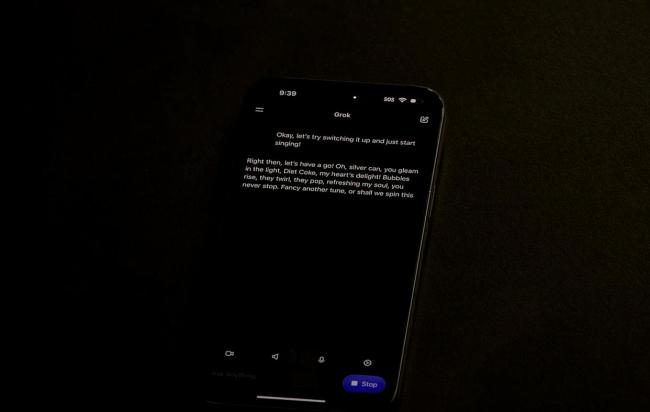
然而,发布直播中的小插曲暴露了一些问题。例如,Grok 4在被要求唱歌时却进入了念诗状态,显示出其在多模态理解方面的不足。此外,发布会的仓促节奏和高管离职的消息也让人联想到内部不稳定。尽管Grok 4技术实力强大,但在面对OpenAI的ChatGPT和Google的Gemini时,真正的竞争在于平台、生态和用户体验。
马斯克在直播中表达了对AI智能超过人类的担忧,但他也表示已经某种程度上接受了这一现实。尽管Grok 4在技术上领先,但用户体验和产品成熟度仍需进一步验证。







